

Drools规则引擎应用简介
规则引擎是一种嵌入在应用程序中的组件,实现了将业务规则从应用程序代码中分离出来,以规则脚本的形式存放在文件或者数据库中,使得规则的变更不需要修改代码即可使用,做到最大程度的灵活。
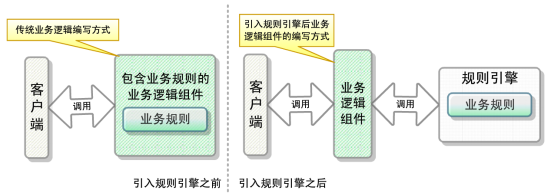
逻辑编写方式对比图
Drools(JBoss Rules)具有一个易于访问企业策略、易于调整以及易于管理的开源业务规则引擎,符合业内标准,速度快、效率高。它是为Java量身定制的基于Charles Forgy的RETE算法的规则引擎的实现,具有了OO接口的RETE,使得商业规则有了更自然的表达。
使用 Drools 可以实现业务逻辑与数据分离:使用对象来保存数据,使用规则文件来定义业务逻辑,这将会从根本上解决程序与业务逻辑之间的耦合,而且,可以动态定义规则文件,让应用程序变得更加灵活。
什么时候应该使用规则引擎?
虽然规则引擎能解决我们的许多问题,但我们还需要认真考虑一下规则引擎对我们的项目本身是否是合适的。需要关注的点有:
(1) 我的应用程序有多复杂?
对于那些只是把数据从数据库中传入传出,并不做更多事情的应用程序,最好不要使用规则引擎。但是,当在Java中有一定量的商业逻辑处理的话,可以考虑Drools的使用。这是因为很多应用随着时间的推移越来越复杂,而Drools可以让你更轻松应对这一切。
(2) 我的应用的生命周期有多久?
如果我们应用的生命周期很短,也没有必要使用Drools,使用规则引擎将会在中长期得到好处。
(3) 我的应用需要改变吗?
这个答案一般情况下是肯定的,“这世界唯一不变的只有变化”,我们需求也是这样的,无论是在开发过程中或是在开发完成以后,Drools能从频繁变化的需求中获得好处。
Drools有一套特定的规则语言,通过该规则语言,可以将不同业务领域的业务“语言”转换为可以被Drools 解读的规则。Drools支持以下四种规则表示方法:The Rule Language、Domain Specific Language(DSL)、Language Decision Tables、XML Rule Language.
本节主要介绍The Rule Language规则语言,其所对应的规则文件以.drl为后缀。主要包括以下部分:
(1) package:声明该规则文件的包名,相当于为规则文件提供一个命名空间,该名称可以不与规则文件所在的目录相关联。package必须要在规则文件的最前面,否则在编译规则文件时,将会抛出错误信息。
(2) import:该关键字就好像Java中的import一样,声明规则在编译和运行时所使用到的Java类。若Java类在package定义的包下,则不需要进行显式导入。除了会将package声明的Java包下全部的类导入外,默认还会导入java.lang包下全部的类。
(3) global:用于定义全局的变量,这些变量可以是具体的数据或者服务对象,规则文件中的全部规则均可以使用global定义的变量。全局变量更多会用于存放规则结果或者与应用进行数据交互。
(4) function:用于在规则文件中定义逻辑语句,其可以将部署逻辑独立存放到规则文件中,这些方法可以供多个规则调用,就像Java类中的工具(private)方法。
(5) query:使用查询可以到工作存储空间中查找符合条件的事实数据,事实数据均会被存放到工作存储空间中,query是其中一种查询这些事实数据的途径。
(6) rule:一个rule定义一个业务规则,当符合某个特定条件时,就执行相应的行为,条件被称为LHS(Left Hand Side),行为被称为RHS(Right Hand Sie),例如使用when LHS then RHS的语法规则定义一个rule.
示例代码:
package com.zuccess.activiti.test;
import com.zuccess.platform.document.model.DocumentType;
//from row number: 1
rule "Row 1 test1"
dialect "mvel"
when
d : DocumentType( parent.type=="000")
then
d.setNote( "ddddd" );
System.out.println("type: "+d.type);
System.out.println("parent type: "+d.parent.type);
end
编写完规则文件后,需要使用Drools 的API 来加载和运行这些文件。这些API 总体来讲可以分为三类:规则编译、规则收集和规则的执行。完成这些工作的API 主要有KnowledgeBuilder、KnowledgeBase、StatefulKnowledgeSession、StatelessKnowledgeSession等,它们起到了对规则文件进行收集、编译、查错、插入fact、设置global、执行规则或规则流等作用。
(1) KnowledgeBuilder的作用就是用来在业务代码当中收集已经编写好的规则,然后对这些规则文件进行编译,最终产生一批编译好的规则包(KnowledgePackage)给其它的应用程序使用。
(2) KnowledgeBase是Drools提供的用来收集应用当中knowledge定义的知识库对象,在一个KnowledgeBase当中可以包含普通的规则(rule)、规则流(rule flow)、函数定义(function)、用户自定义对象(type model)等。KnowledgeBase本身不包含任何业务数据对象(fact对象),业务对象都是插入到由KnowledgeBase产生的两种类型的session对象当中(StatefulKnowledgeSession和StatelessKnowledgeSession),通过session对象可以触发规则执行或开始一个规则流执行。
(3) StatefulKnowledgeSession对象是一种最常用的与规则引擎进行交互的方式,它可以与规则引擎建立一个持续的交互通道,在推理计算的过程当中可能会多次触发同一数据集。在用户的代码当中,最后使用完StatefulKnowledgeSession 对象之后,一定要调用其dispose()方法以释放相关内存资源。
(4) StatelessKnowledgeSession 的作用与StatefulKnowledgeSession相仿,但它对StatefulKnowledgeSession做了包装,使得在使用StatelessKnowledgeSession对象时不需要再调用dispose()方法释放内存资源。
示例代码:
//创建规则构建器
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder();
kbuilder.add(ResourceFactory.newByteArrayResource(ruleDef.getRuleDrl()), ResourceType.DRL);
//创建规则构建库
KnowledgeBase kbase = KnowledgeBaseFactory.newKnowledgeBase();
//构建器加载的资源文件包放入构建库
kbase.addKnowledgePackages(kbuilder.getKnowledgePackages());
//创建会话
StatefulKnowledgeSession ksession = kbase.newStatefulKnowledgeSession();
for(int i=0; i<objList.size(); i++) {
ksession.insert(objList.get(i));
}
ksession.fireAllRules(); // 触发所有规则执行
ksession.dispose();
Drools规则引擎实现了业务逻辑与业务规则的分离以及业务规则的集中管理,也越来越发展完善,如果我们想更灵活地使用Drools,还需要通过更多的实际应用积累经验,最重要的是学会如何将实际的业务转换为具体的规则语言。
